

Practical intermediate database tips
August 15, 2020
|by Alexander
This guide is for people who know a little about how databases and SQL work, and are venturing into setting up a database and writing SQL in production to serve real customers for the first time. We're assuming Postgres since it's the most popular database, but the advice is generally applicable to other relational databases.
This guide assumes:
- High level understanding of the purpose of a database and can use one for CRUD operations.
- How to form basic queries. Select columns where conditions apply. Combine tables with JOIN when the query spans multiple tables.
This guide is not:
- beginner intro on what SQL is and can do
- advanced topics of squeezing optimizations from queries for > 5-6 figures of QPS (queries per second)
- theory on database internals
Measure
Set up measurements early on. They're inexpensive and easy to do. The basis of every change you make in tuning your database performance should be rooted in measurements. Bottlenecks are often not where you expect, and if you make an optimization somewhere where there is not a bottleneck, you haven't made an optimization at all.
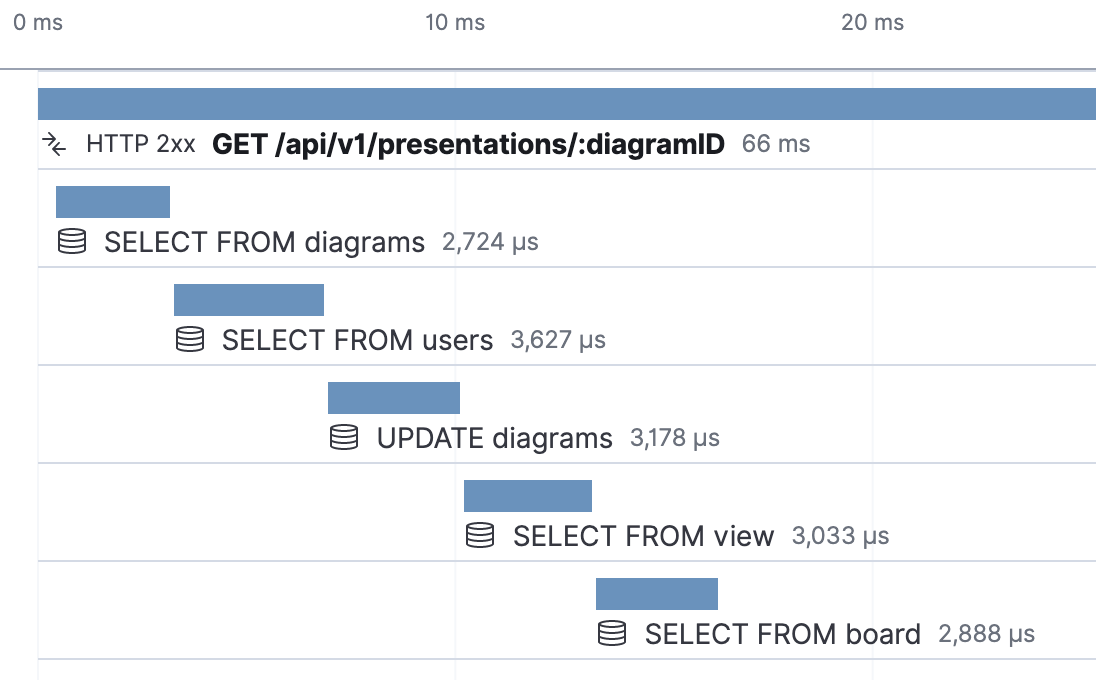
Check every once in a while for anomalies manually, but automate as much as you can with alerts. Setting up threshold alerts preemptively is generally hard to get right, because without historical data, your predictions of what to set the thresholds to will probably be off (e.g. alert me when query takes longer than X). Preemptively setting up alerts for relative differences is a good start. For example, alerting every time your average time for a query has dropped by 10% can be a regression test.
Speaking of averages, you should split up your measurement reporting in terms of percentiles (in general, not just for databases); e.g. p99, p95, p75, and p50. This categorization essentially tells you, "how slow is the slowest 1% of queries", and "how slow is the average query". It's normal for 1% of your queries to take much longer than your average (e.g. a large customer with 10x data than others). Having p50 drop significantly after a code change is potentially rollback-urgent, while a p99 drop is likely an edge case bug.
If you're an up-and-coming online store and anticipating unprecedented traffic on a holiday, your historical measurements don't reveal how well your database would handle orders of magnitude higher loads. In addition to your passive, continuous measurements on everyday real traffic, you should occasionally perform load testing.
- Identify a low-traffic time to avoid disrupting actual customers.
- Write a script that mimics real data access patterns and amplify to whatever peak traffic you anticipate in your most optimistic scenario.
- Run it against your production database. Unless you have a staging infrastructure that has the exact same configurations and data running on the same spec of computers, it's that's the only truthful test that your database will gracefully handle peak traffic. Better to have the few customers during low-traffic hours have a bad time than going down when it matters most.
Learn more: https://www.datadoghq.com/blog/sql-server-monitoring/
SQL Commands
The most encompassing advice for how not to shoot yourself in the foot is to be specific in your SQL commands. The specificity is the main advantage of writing raw SQL over using an ORM. Most performance hits caused by formation of SQL queries is due to lack of specificity. If you just want to find the first instance of something, don't SELECT * FROM something and do the filtering in the application. Use LIMIT 1 to halt searching early, SELECT only the columns you care about to avoid the unnecessary network bandwidth. If you want to find rows of data where a column has the same value in two tables, don't SELECT from both and for loop to combine in application -- use JOIN. Database's have incredible optimizers for SQL commands, but it can only work with as much context as you provide it. Whenever I find myself applying a transformation to the data returned or filtering some out, I ask myself whether it's possible to do in SQL instead.
Many simply don't know what the database can do. For example, instead of computing the current datetime and subtracting 1 in your application and passing that for a WHERE clause, you can instead do AND created_at >= now() - INTERVAL '1 DAY'. You don't need to memorize all the intricacies of Postgres, just search whatever you need to do in your application as it comes up. The chances that your use case is so unique that you have no choice but to write application logic for each row is rare.
There's not a lot to the SQL syntax. Be aware of the existence of commands and common functions. Since SQL is declarative programming, there might be some unfamiliar ways of doing things if you've only been exposed to imperative programming. My advice is to just Google whatever you want to do when it's the first time you're doing it. Which join should you use (there's multiple types)? Just search what you want to do in generic terms, open up a CLI and play around with it.
Learn more: https://codecademy.com/articles/sql-commands
Security
To scratch the surface:
- Whitelist access to your database to your application hosts and admin hosts, preventing access from unauthorized hosts even if they have your credentials.
- Use appropriate roles/permissions. For application access, you should really just be deciding between readonly and readwrite. You almost certainly don't need to be creating, altering, or dropping tables programmatically.
- Perform regular backups. Periodically (once a month), check that it's working. Keep this isolated from your production databases. If everything goes wrong, you only lose data from $TIME_OF_HACK - $TIME_OF_BACKUP.
In terms of application security, there is only one attack vector, and that is SQL injection.
As much as you can, don't let user input pass through to SQL queries. Interpret, validate, sanitize.
This is by no means comprehensive. Seriously protecting your customer's data means setting up automated alerts, auditing, robust logging, encrypting data at rest, etc.
Indexes
Indexes can be thought of as an optimization option where you trade space and edit performance for query performance. If a column is accessed much more frequently than it is edited, and you notice a query taking unusually longer than others in your measurements, throw an index at the column and remeasure. An index can make the difference between your app being unusably slow and happy users marveling at how snappy it is.
Didn't notice any improvement in query time after adding an index? You probably added the index on the wrong column, or the query is doing something you don't expect. You can investigate one level down by using the EXPLAIN command. This gives insight into the "execution plan", which is the approach the database will use to execute the query. In it, there's a "node type" which can reveal whether or not it's using the index vs doing a full scan vs something else, as well an estimate on the number of rows it expects to search. For example, one gotcha is that if you're filtering by WHERE somefunction(indexedColumn), it won't actually use the indexedColumn index (you need to define an index on the function of it). There's going to be unexpected behavior, so double confirm that your index is indeed helping and not just hindering edit/insertion performance unnecessarily.
If you have a particularly troublesome query, you might consider adding a "composite index", which means an index on multiple columns. There's often some surprising behavior here; for example, order of column constraints matter. We're now venturing into query optimization territory. If a single index isn't doing the job, you should read up on how to properly optimize — with indexes and beyond.
Learn more:
- https://docs.gitlab.com/ee/development/understanding_explain_plans.html
- https://www.postgresql.org/docs/12/indexes-multicolumn.html
Scaling
Vertical scaling is beefing up the computer the database runs on, and horizontal scaling is adding more computers that run the database and distributing the load among them. Vertical scaling costs more money, while horizontal scaling costs more brainpower and effort.
Don't scale prematurely until you've done measurements and load testing to identify you need to. If you're running on a single node and you're only scaling to handle an anticipated increase in load, e.g. front page on Hacker News, scale vertically beforehand and scale down after. If you're running into consistently high loads, identify whether the bottleneck is query processing time (CPU spikes) or disk space (disk allocation near threshold or I/O usage increases due to exceeding cache limit):
- If CPU: scale horizontally via replication. Every node is running with the same data, and queries can be distributed to whichever is currently using the least CPU (or just round-robin).
- If disk space: scale horizontally via sharding, which is to split up your data by predetermined keys. You can then replicate certain shards if needed, like if you have some power users that frequently update their data. Sharding is easy to get wrong, and mistakes are costly if not catastrophic. Don't go down this route until you identify a clear need.
Caching
An alternative method of horizontal scaling is caching. Databases have in-memory caches, which are just pages of data held in an LRU (least recently used) store, but there's obvious benefits of expanding this to a separate server.
- Isolation rom the actual database, so cached operations don't affect CPU.
- Data locality to decrease latency.
- Granular control of what data resides in the cache. Redis can do things like explicitly set an expiry time for each data.
In terms of cost, vertical scaling > horizontal scaling > caching. However, whether or not you can get away with using a cache in place of scaling out your database depends on your data patterns. For example, if one user sets a piece of data that many users will then access, unchanged, for some duration of time, and your cache has a much lower latency to hit than your database, then that is an excellent use case. If you just want to increase the performance of a set of queries but these queries are changing very frequently, then your cache will be continuously populated with new data, fill up very quickly, and not provide utility. The primary consideration is that caching can introduce more latency due to the addition of a network hop, and, perhaps more insidiously, it increases complexity in your application code.
Learn more:
- https://en.wikipedia.org/wiki/Five-minute_rule
- https://www.infoq.com/articles/postgres-handles-more-than-you-think
Multiple environments
You should have, at the very least, a separate dev environment for your database. It can just be a local instance running on your laptop, but you should never be applying experimental schema changes on a production database. For every schema change made on the dev database, create individual migrations with pg_dump, so that when you want to roll back, you can find the migration at that point in time.
Your dev environment is not meant to mirror the quantity or shape of data in production, but merely to develop with to verify your SQL commands are working. Ideally, you have another database that's halfway between your dev and your production databases (some call it "staging" or "testing"). It can have real data — maybe export once a week/month from your production database (don't forget to redact sensitive data to reduce exposure), so that you can get a sense of how queries would actually perform in production without experimenting in production. It can be located in the cloud, so you get a little closer to production environments with similar latency. The configurations should be as close to production as possible (e.g. set same timeout params). You can use it to programmatically run hermetic integration tests.
You should also have a separate environment for running analytics against. Often times a company's analytics database is a completely different type than their production database, since the access patterns are so different, and because data from multiple sources are combined together.
Learn more:
Connection pooling
When your application connects to a database, it reuses existing connections so as to avoid the overhead of establishing TCP connections redundantly, something that is especially taxing if your database needs to do an SSL handshake every time. A connection pool refers to connections which are already established and are sitting idle waiting to be reused. It's an application-level concept — not a database one.
One of the configurations you can set is the min number of idle connections and max number of connections. These settings depend on your traffic patterns, but you never want to hit the max number, which would mean your application is sitting around — potentially during a live customer request — for another connection to free up. Postgres defaults to 100 max connections, but if you're using a cloud provider, it will most likely vary (e.g. AWS uses the formula MIN({DBInstanceClassMemory/9531392}, 5000)).
The cost of idle connections is not trivial. On top of the memory each one reserves on the database, there's logic for each command that deals with which connection is holding which lock. So how do you determine how many to maintain? Measure how many concurrent threads your application can actually use at any given moment when communicating with your database. This is technology dependent, ranging from language limitations, to framework configurations, to the number of cores your server is running on. Test with a large load of concurrent requests, and spew metric counts of how many threads are spun up.
Learn more:
Transactions
A transaction is a group of commands where they all get committed or none do. This is enforced by rolling back previous commands in the transaction when one fails. Until the entire transaction is committed, none of the changes are visible outside the transaction. The classic use case example is transferring money: you wouldn't want to deduct money from the sender and, under any circumstance, not also add money to the receiver.
You should use transactions very frequently. They are cheap — in Postgres, all individual commands are actually just single-command transactions. It is, in fact, often faster to wrap some insertion-heavy batch of commands around a transaction because you avoid the overhead of committing multiple times.
One edge case to watch out for is that transaction data is saved in the database memory as opposed to disk. This means you could potentially run out of space in a long-running transaction. Memory usage is one thing your metrics should be reporting, and it's pretty straightforward to avoid this.
Learn more:
- https://cs186berkeley.net/static/notes/n10-Transactions.pdf
- https://postgresql.org/docs/8.3/tutorial-transactions.html
Conclusion
These are some of the things that have helped me as I set up Terrastruct's database infrastructure. To learn more about using data in applications in general, this is the best book I've read on the subject: https://www.amazon.com/Designing-Data-Intensive-Applications-Reliable-Maintainable/dp/1449373321
Did I miss anything? Have any questions? My inbox is open: alex@terrastruct.com.